TODO
SnowMirror team proudly announces the new SnowMirror for Salesforce which has been rewritten from scratch and brings many new features similar to those in the ServiceNow version. This release is fully compatible with Salesforce Winter ’18 Release. The main SnowMirror benefits are:
- Salesforce read replica in a traditional on-premise database which allows seamlessly building reports using existing reporting platforms and popular BI tools
- Backup tool for individual Salesforce tables including scheduled backups and configurable retention policies
- Mirror database as an integration hub for Salesforce data
Please download a trial version and evaluate SnowMirror in your own environment.
What’s New
New Replication Algorithm
The synchronization algorithm has been revised and thoroughly tested using large Salesforce organizations.
Salesforce Backup
This is a completely new module provided by the SnowMirror team. SnowMirror is now a fully-featured backup tool for individual Salesforce tables including full, differential and incremental backups with configurable retention policies.
Attachment Replication & Backup – SnowMirror enables replicating attachments onto a filesystem as well as performing attachment backups. The retention period settings is available as well. The attachments are stored in a directory structure where each record has its own folder named by the record’s display value and the folder contains the attachments as standard files.
Schema Changes Notifications – SnowMirror notifies every time there is a new field in a Salesforce object. It works for the modified or removed fields as well. The notifications work independently on the Auto Schema Update feature. So even if the schema is not being updated automatically then users get notified about changes on the Salesforce side.
Edit Mappings – This new feature allows editing database column data types for individual fields. So it is possible to override the default SnowMirror mapping. E.g. it is possible to extend a varchar column to CLOB and such a setting persists even if the temporary tables are being used for the full loads. See the feature in the user manual.
LDAP Integration – SnowMirror allows you to integrate it with corporate Active Directory or LDAP. When selecting this security realm then the users are not being stored in the configuration database anymore but they are being authenticated against LDAP. The existing roles are being mapped to groups in LDAP.
Salesforce is the leading cloud platform for automating sales and customer service processes. But Salesforce is not only about Service Cloud or Sales Cloud products. It is a real cloud platform for a wide variety of enterprise solutions. As a result, every Salesforce instance contains valuable, important or critical data.
If Salesforce is being implemented by a large organization with many other applications, existing IT environments and preferred company-wide solutions, then the Salesforce’s single system of record is suddenly becoming only another piece of software, another data source.
By its cloud nature, it is much more complicated to work with the Salesforce data outside of the cloud and making integrations directly with the production Salesforce instance might complicated, expensive or even impossible especially while dealing with bulk data. This is why many Salesforce customers think of building their own read replicas to be able to work with the data on-premise.
Specifically, here are 3 reasons to keep an independent copy of your Salesforce data:
1. Reporting and Business Intelligence
What if you have an existing data warehouse? Do you have a standard reporting environment based on Tableau or Cognos? In this case, Salesforce is just one of the data sources for the reporting team and accessing the cloud instance is simply not flexible enough. Having a copy of the Salesforce data in a more traditional relational on-premise database such as Oracle or SQL Server makes everything much easier.
One approach is to connect the reporting tool directly to the mirror database, the other approach is to use the replica as a staging area for further ETL processing such data mart loads or data blending.
2. Simplified Integrations
Salesforce data is important for many other applications within an IT environment of a company. Other tools need to work with the contacts, cases, leads and other objects. The experience is that vast majority of applications working with Salesforce data does not modify the data at all. These are just read-only Salesforce integrations.
In this case, the best practice is to read the data from a mirror database instead of using Salesforce API to get the same records again and again.
3. Disaster Recovery and Business Continuity
Business Continuity and Disaster Recovery are closely related practices that describe an organization’s preparation for unforeseen risks to continued operations. Many organizations are required to have such plans. Having the Salesforce data in a separate location is the vital part of these plans to cover scenarios such as “What if there is no Salesforce anymore?”.
Replicate Salesforce Data with SnowMirror
SnowMirror is a smart replication tool for Salesforce. The data is loaded from a Salesforce instance and stored in a relational database such as Oracle or Microsoft SQL Server, installed in a local environment. SnowMirror is simple to install and configure. Follow the quick start guide to set up SnowMirror just in 10 minutes.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
A regular backup of your ServiceNow data is critical. In the previous post we have described why it was necessary to perform independent backups of individual tables using tools such as SnowMirror Backup. While knowing you have regular snapshots of your ServiceNow data, the real challenge can be restoring that data and relationships in the event of a data loss. Now, let’s look at the options that we have to restore tables from backups.
If you want to restore a table from backups then you start with the latest (or target) full backup and then you restore the latest differential backup. If the incremental backups are being used then you have to restore all increments since the last full backup.
SnowMirror is able to backup ServiceNow tables into two formats: CSV and native ServiceNow XML. These formats are the same or very similar to those created by ServiceNow export features. Depending on a backup format the restore strategies are different.
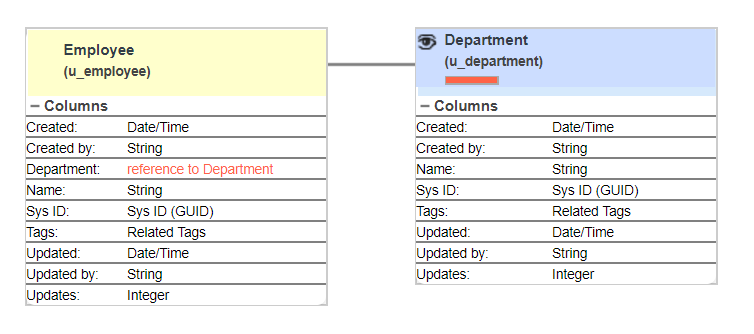
Example Data Model
In this example we have a very simple data model consisting of two tables Employee and Department. They both have the Name field and each employee has a reference to a department.
Native ServiceNow XML
Using the native XML format for backups and then the restore process is the most straightforward way and it has many benefits. On the other hand, it is a low level ServiceNow feature which does not allow any mistakes. Incautious data upload might create even more damage to the ServiceNow data.
The benefits are clear:
- The restore procedure is extremely simple.
- Existing records are updated and new records stay untouched. The missing are restored of course.
- The sys_ids remain the same which is very good for referential integrity.
- References can be restored in any order.
This is how the table looked like before the restoration started. Please note the record Radek which was not in the backup file, missing record Jana and an updated record Pavel:
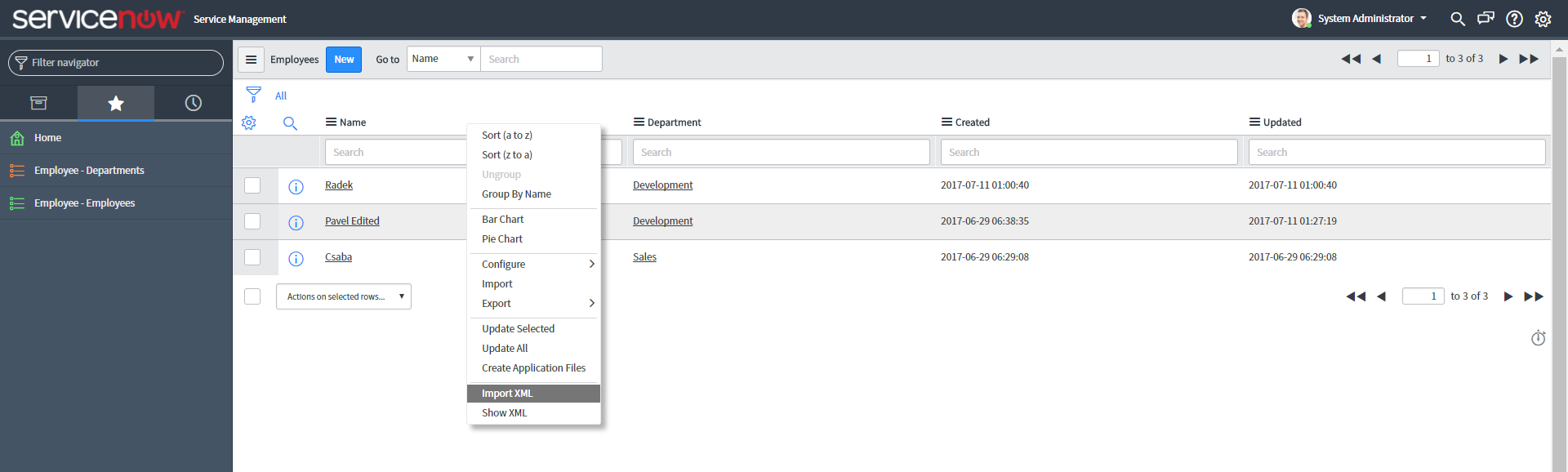
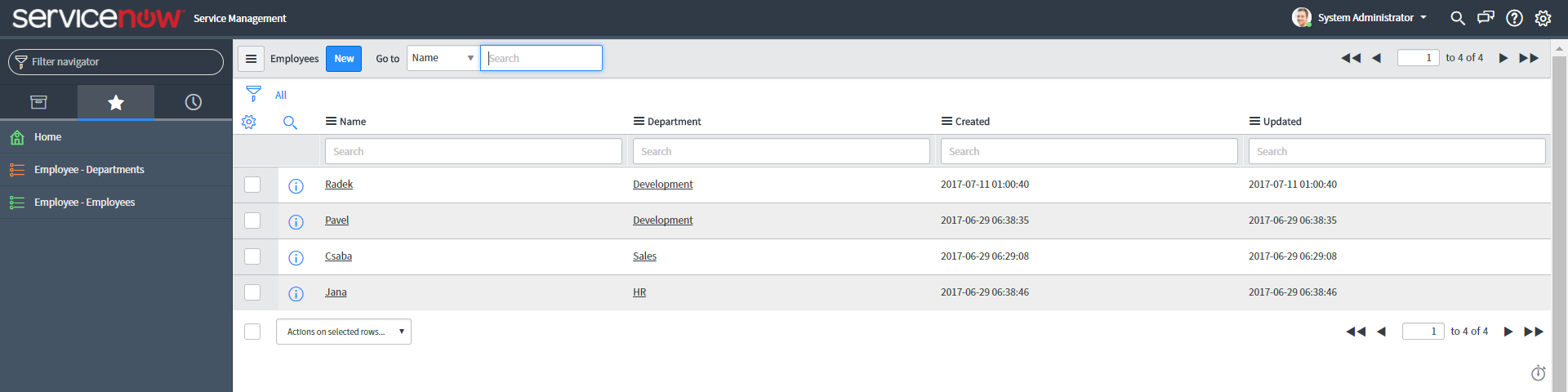
After executing the Import XML command the table is restored including all references. Please note that Radek stayed in the table, Pavel got updated and Jana is restored:
CSV
Restoring data from a CSV file is a bit more complicated, on the other hand, the whole process is under your full control and it is easier to adjust the data to your needs. The ServiceNow Import Sets have many features and they are well described in the documentation.
Here is a list of steps and hints to make the restore easier.
- Create a new Data Source from the CSV file.
- Create a Transform Map for the table to restore.
- Use the Auto Map Matching Fields feature to map all fields from CSV to the target table
- Select a coalesce field to make the updates work. Either a unique field (e.g. incident number) or a sys_id. See below.
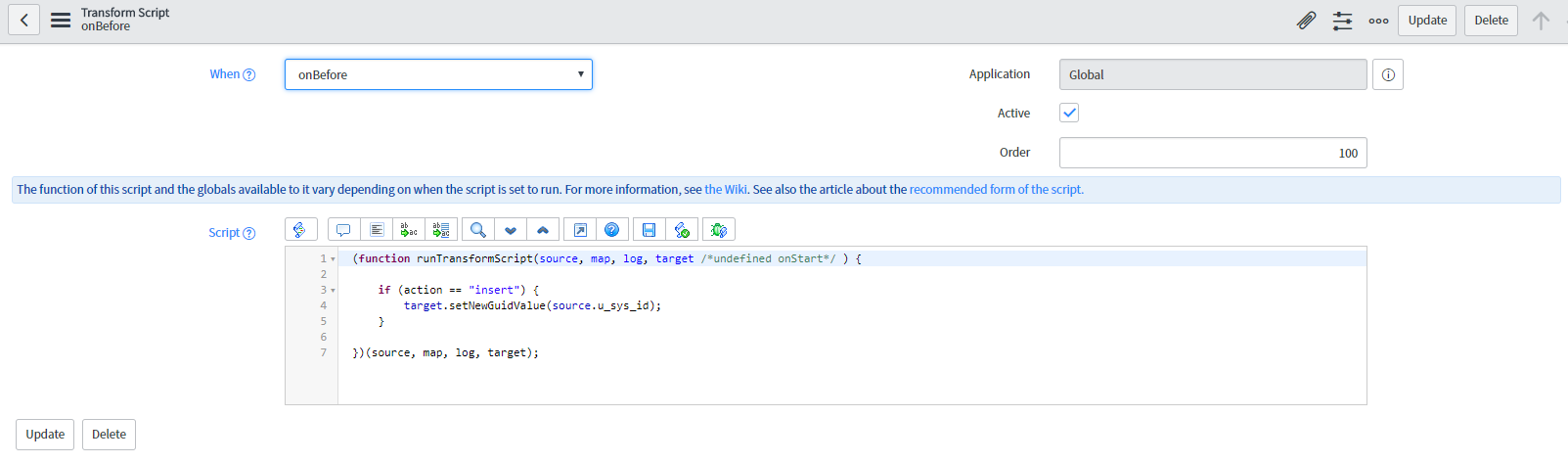
Updating existing records during the recovery is vital otherwise the import set creates new records instead, Using a unique field to coalesce the records is not always possible or it is not the best way. If you want use sys_id for this purpose then it is necessary to add this mapping to the field map manually by mapping the source u_sys_id to the target sys_id and making them as coalescing values.
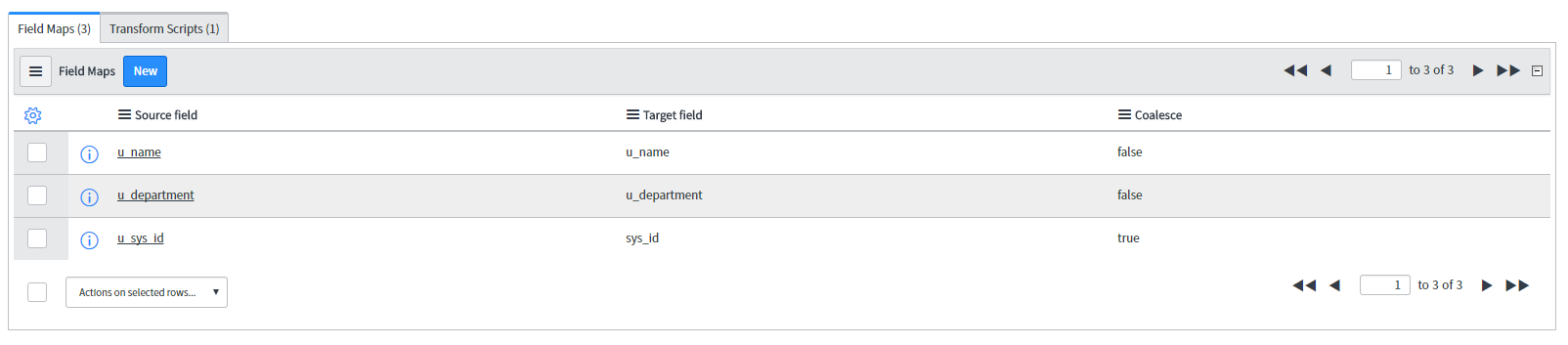
This technique ensures that updates will be executed correctly, however, the inserts will be created with generated sys_ids and not with the sys_ids from the backup file, which might break relationships with other tables. To ensure the inserted records get a sys_id from the file create an onBefore transform script like this:
Restoring relationships (references to other records) with CSV is much more complicated than with the XML format. In the ideal world the correct restore procedure is to start from the tables that are being referenced and then continue with the rest. But not all of the data model are trees.
By default, CSVs contain display values of referenced records and the transform process finds the references using display values. However, what if the referred record is not there (yet). ServiceNow would either create it or cancel (ignore) the relationship. This is configurable. None of these options are ideal for the recovery process.
SnowMirror Backup allows you to include sys_ids of the references into the CSV backups which is not available in the standard ServiceNow exports. It helps with record identification but not with the missing references. This has to be resolved by custom scripts inserting reference sys_ids even for missing references. In this case the order of restored tables does not matter.
Webinar: How to Backup ServiceNow Data
The latest SnowMirror 3.8 fully supports the ServiceNow Jakarta release and it introduces the possibility to connect SnowMirror with a corporate Active Directory or LDAP. Please note that older SnowMirror releases do not work with Jakarta correctly.
Active Directory Integration
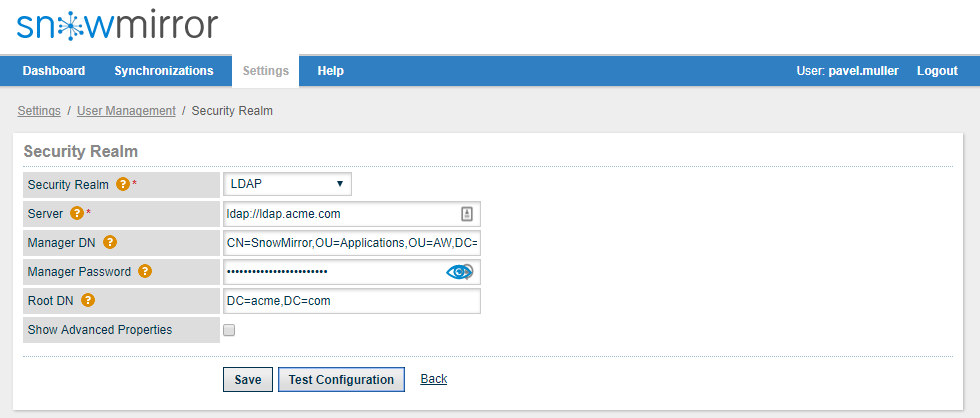
The new feature allows configuring a Security Realm in Settings -> User Management. It is either possible to use internal SnowMirror database for storing users and credentials or to connect SnowMirror to LDAP. Both Active Directory or generic LDAP connections are supported.
User login is then authenticated against LDAP and no credentials are being stored in SnowMirror. SnowMirror reads user groups from LDAP too and maps them to SnowMirror roles. E.g. create SYNCHRONIZATION_ADMIN group in LDAP and add a user as a member into this group. After authentication SnowMirror assigns Synchronization Admin to such a user. Read more about LDAP settings in the Admin Guide.
Jakarta Support
Jakarta release brings several undocumented changes in the out-of-the-box API and related plug-ins. SnowMirror algorithms were revised and adjusted to these changes. Please note that older releases do not work with Jakarta correctly. Especially the Consistency Check feature is affected. If you plan upgrading to Jakarta then the upgrade to SnowMirror 3.8 is required too.
It was great talking with you at the booth about our tools. You can download SnowMirror datasheets and watch a quick demo.

Let’s schedule a demo!
SnowMirror Overview
SnowMirror Datasheet

Click the PDF link bellow to learn more.
SnowMirror Backup Datasheet

Click the PDF link bellow to learn more.
It was great talking to you at the booth about our tools. Now you can download SnowMirror datasheets and watch a quick demo.
Let’s schedule a demo!
SnowMirror Overview
SnowMirror Datasheet
Click the PDF link bellow to learn more.
SnowMirror Backup Datasheet
Click the PDF link bellow to learn more.